









服務熱線
0755-83044319

發布時間:2023-01-10作者來源:芯智訊瀏覽:2486

1月6日消息,AMD 在 CES 2023展會上推出了下一代面向數據中心的APU產品Instinct MI300,其采用chiplet設計,擁有13個小芯片,晶體管數量高達1460億個。

具體來說,Instinct MI300由13個小芯片整合而成,其中許多基于3D堆疊的,擁有24個Zen4 CPU 內核,并融合了CDNA 3 圖形引擎,以及共享的統一內存池,包括 Infinity Cache 高速緩存和8個HBM共享內存設計。總體而言,該芯片擁有1460億個晶體管,超過了英特爾的1000億晶體管的Ponte Vecchio,成為了AMD投入生產的[敏感詞]芯片。

從曝光的照片可以看到,MI300兩側擁有八個共計128GB的HBM3芯片,在這些 HBM3芯片之間還放置了多個小塊結構的硅片,以確保冷卻解決方案在封裝頂部擰緊時的穩定性。
MI300的計算部分由9個基于臺積電5nm工藝制程的小芯片組成,這些小芯片包括了CPU和GPU內核,但AMD并未提供每個小芯片的詳細信息。


由于Zen 4 內核通常部署為八個核芯,因此24核CPU則意味著有3個小芯片是CPU芯片,另外6個則是GPU芯片。GPU芯片使用AMD的CDNA 3架構,這是AMD數據中心特定圖形架構的第三個版本。AMD 尚未明確CU數量,不過官方公布的數據顯示,CDNA 3的每瓦特AI性能達到了上代CDNA 2的5倍。

這9個小芯片是通過3D封裝堆疊在4個6nm小芯片上,這些芯片不僅僅是無源中介層——這些芯片是有源的,可以處理I/O和各種其他功能。
AMD 代表展示了另一個 MI300 樣品,該樣品打磨了頂部模具,以揭示四個有源中介層模具的結構。可以清楚地看到內部結構,這些結構不僅可以在I / O瓦片之間實現通信,還可以實現與HBM3堆棧接口的內存控制器之間的通信。但是這個樣品禁止拍照,因此沒法提供照片。
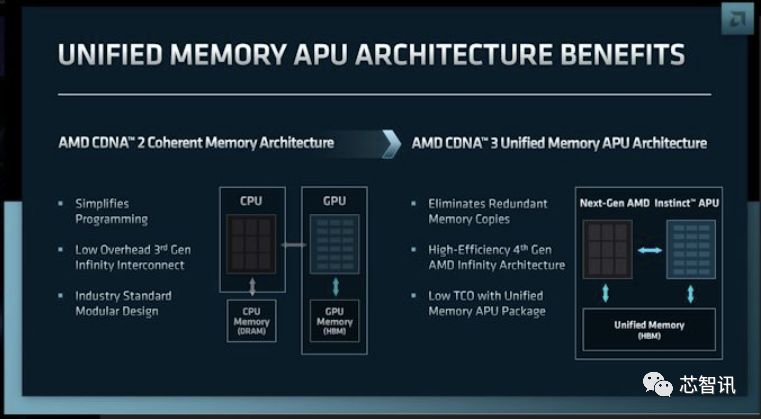
3D堆疊設計允許CPU、GPU 和內存芯片之間實現令人難以置信的數據吞吐量,同時還允許 CPU 和 GPU 同時處理內存中的相同數據(零拷貝),從而節省功耗、提高性能并簡化編程。看看該設備是否可以在沒有標準DRAM的情況下使用會很有趣,正如我們在英特爾的Xeon Max CPU中看到的那樣,它也采用了封裝上的HBM。
AMD的代表不愿透露更多細節,因此不清楚AMD是否使用標準的TSV方法將上下芯片連接在一起,或者是否使用更先進的混合鍵合方法。AMD表示,將很快分享有關封裝方面的更多詳細信息。
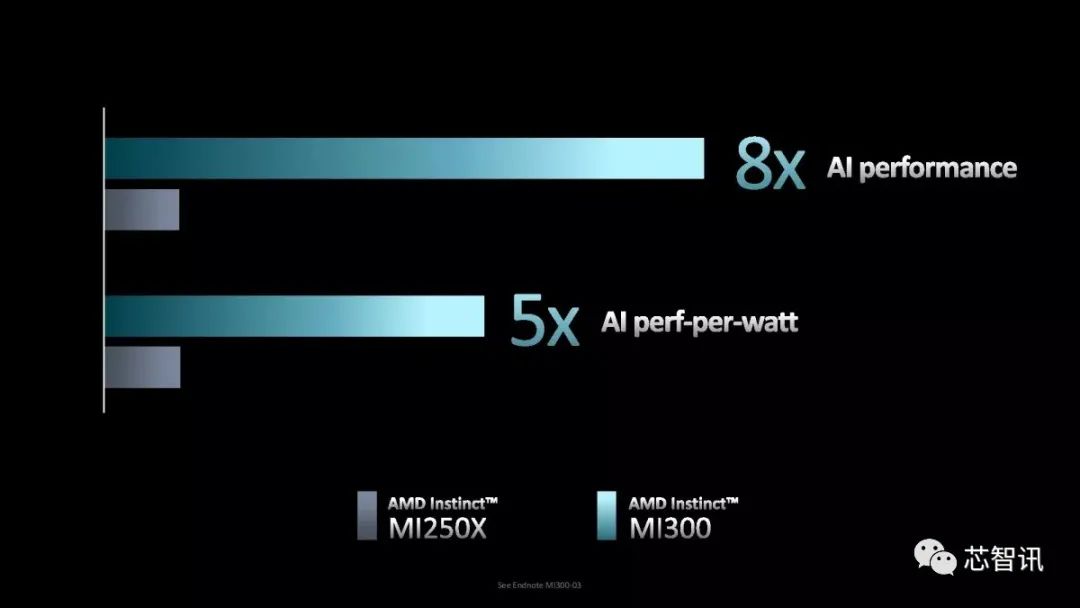
AMD聲稱MI300提供的AI性能和每瓦性能是Instinct MI250的8倍和5倍(使用稀疏性FP8基準測試)。AMD還表示,它可以將ChatGPT和DALL-E等超大型AI模型的訓練時間從幾個月減少到幾周,從而節省數百萬美元的電力。
當前一代的Instinct MI250為世界上[敏感詞]臺百萬兆級超級計算機Frontier提供動力,Instinct MI300將為即將推出的美國新一代El Capitan超級計算機提供動力,其FP64 峰值計算性能高達200億億次(2 ExaFLOPS)。

AMD表示,這些面向超級計算機的MI300芯片將昂貴且相對罕見——這些不是大批量產品,因此它們不會像EPYC Genoa數據中心CPU那樣廣泛部署。但是,該技術將過濾到不同外形尺寸的多個變體。
該芯片還將與Nvidia的Grace Hopper Superchip競爭,后者是在同一基板上整合了Hopper GPU和Grace CPU。這些芯片預計將于今年上市。基于Neoverse的Grace CPU基于Arm v9指令集,配備了兩個與Nvidia新品牌的NVLink-C2C互連技術融合在一起的芯片。AMD的方法旨在提供卓越的吞吐量和能源效率,因為將這些設備組合到單個封裝中,通常比連接兩個單獨的設備時能夠在單元之間實現更高的吞吐量。
MI300還將與英特爾的Falcon Shores競爭,后者將具有不同數量的計算模塊,包括x86內核,GPU內核和內存,具有令人眼花繚亂的可能配置,但這些要到2024年才能到來。

在這里,我們可以看到MI300封裝的底部,其中包含用于LGA安裝系統的接觸墊。AMD沒有分享更多細節,該芯片目前正在AMD的實驗室中。

AMD預計將在2023年下半年交付Instinct MI300,屆時El Capitan超級計算機將首發部署MI300,有望成為世界上最快的超級計算機。
值得一提的是,英特爾聯合阿貢國家實驗室也在部署運算速度高達200億億次極光(Aurora)超級計算機,該超級計算機基于英特爾的擁有超過1000億個晶體管的Ponte Vecchio數據中心顯卡。
免責聲明:本文采摘自“芯智訊”,本文僅代表作者個人觀點,不代表薩科微及行業觀點,只為轉載與分享,支持保護知識產權,轉載請注明原出處及作者,如有侵權請聯系我們刪除。
友情鏈接:站點地圖 薩科微官方微博 立創商城-薩科微專賣 金航標官網 金航標英文站
Copyright ?2015-2025 深圳薩科微半導體有限公司 版權所有 粵ICP備20017602號
